
实验报告
思考题
Thinking 2.1
在编写的 C 程序中,指针变量中存储的地址被视为虚拟地址。
MIPS 汇编程序中 lw 和 sw 指令使用的地址被视为虚拟地址。
参见实验指导书:
在计算机组成原理等硬件实验中,CPU 通常直接发送物理地址,这是为了简化内存操作,让大家关注 CPU 内部的计算与控制逻辑。而在实际程序中,访存、跳转等指令以及用于取指的 PC 寄存器中的访存目标地址都是
虚拟地址。我们编写的 C 程序中也经常通过对指针解引用来进行访存,其中指针的值也会被视为虚拟地址,经过编译后生成相应的访存指令。
Thinking 2.2
用宏实现链表的好处
首先,在可重用性上自然是能够被多次反复使用,便于代码书写与阅读。
其次,宏相较于函数,其自由度大大增加。它可以支持不同数据类型的链表,因为其本质上只是字符串替换,可操作性更强。
第三,宏不是函数调用,不需额外占用函数栈空间。
比较单向、双向、循环链表
由于 /usr/include/sys/queue.h 里面的双向链表和我们自己实现的差别不大,因此都使用了/usr/include/sys/queue.h的进行对比分析。
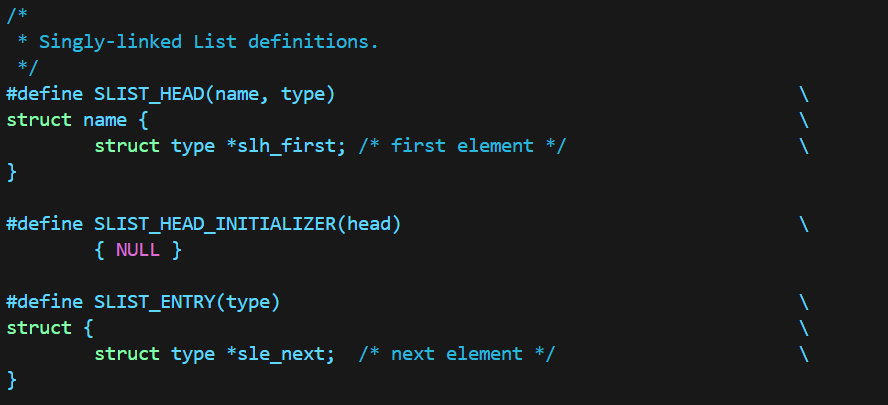
单向链表:
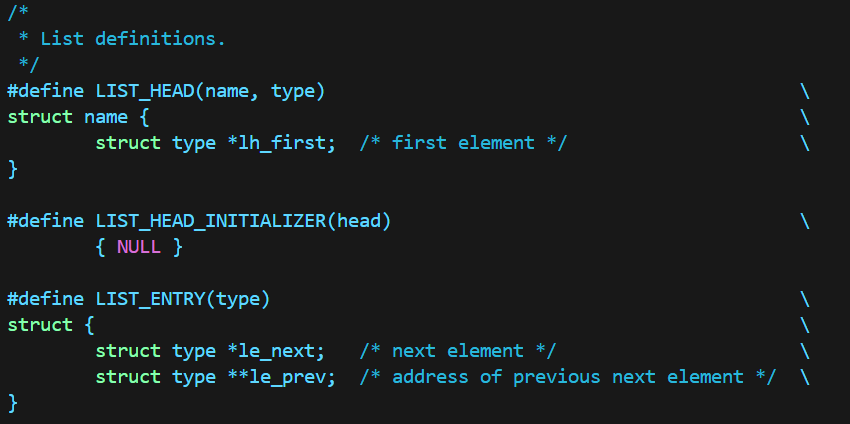
双向链表:
循环链表:
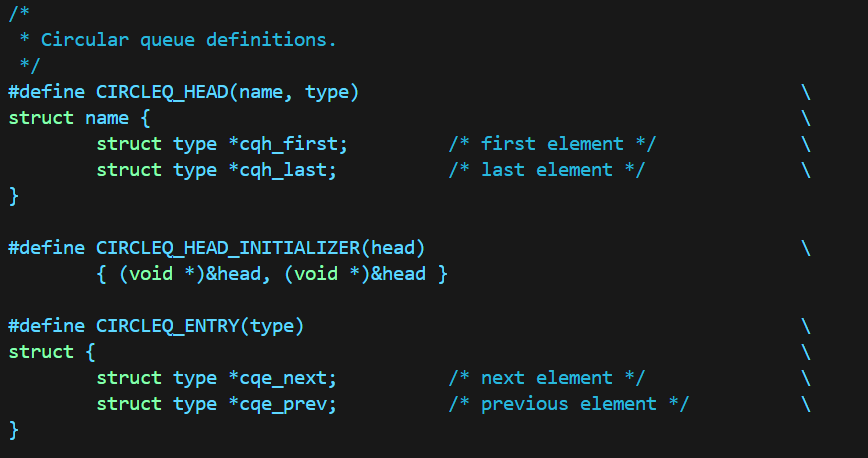
可以看出,在结构体定义上,单向链表与双向链表都只需要头指针,而循环链表需要头尾两个指针;
在link定义上,单向链表只有next,而双向链表与循环链表都有next与prev。
需要注意的是:循环链表的next与prev都是数据的指针,而双向链表的prev是前一数据的next指针的指针!
在功能性上的差异在此不再赘述了,实现的功能越多,效率上可能就会有折损。
- 插入
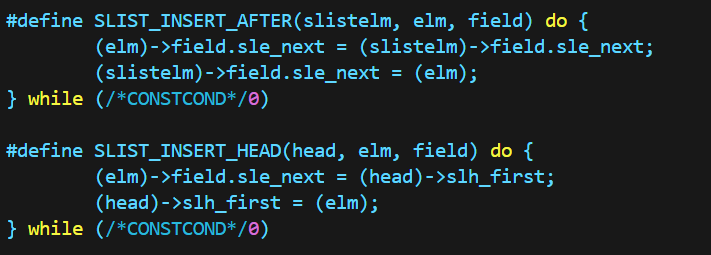
单向链表只能实现插入到某个节点之后,但相应的语句也只有两条。
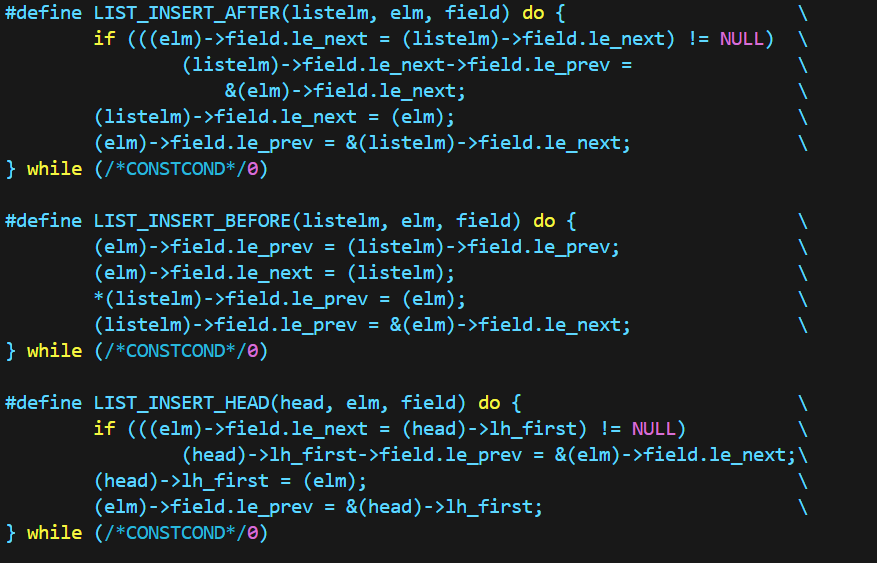
双向链表能够实现插入到前、后两种位置,但是每个方法都需要四条语句。
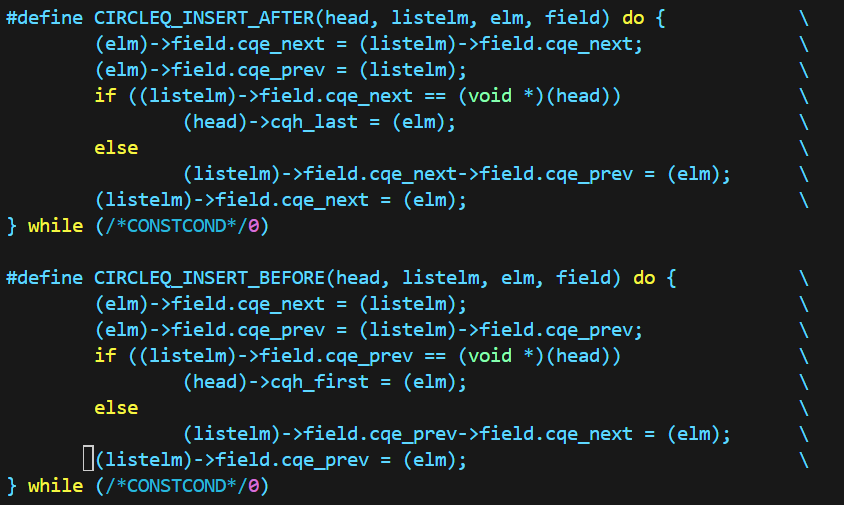
循环链表能实现插入到前、后两种位置,需要的语句更加复杂。
此外,循环链表出了插入到HEAD之外,还有独有的插入到TAIL - 删除
三种链表在删除上的区别更加显著:
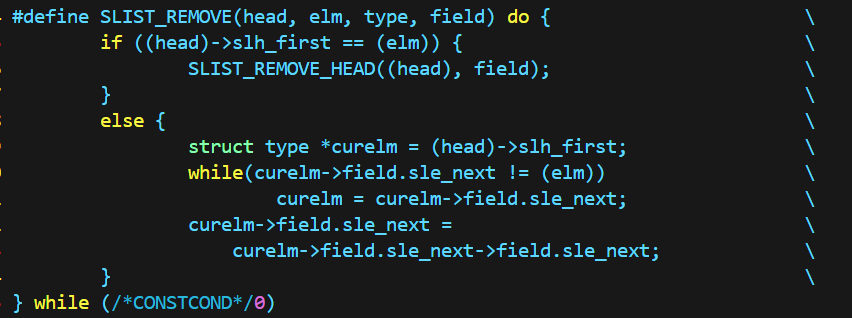
单向链表要想删除某个结点,必须通过遍历来定位好他的位置,才能让它前面的结点链接上它后面的结点。
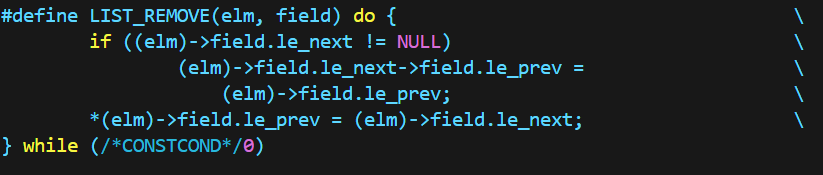
而双向链表可以直接知晓其前一结点的next指针,因此只需要O(1)的操作

循环链表也是O(1)的,但是对于head指针要特殊处理。
整体来看,双向链表是权衡了时间复杂度与空间复杂度的不错设计,性能优良。
Thinking 2.3
选择C项。
接下来分析一下Page_list的结构。
Page_LIST_entry_t
结合

与
![]()
得知
|
|
构成了结构体Page_LIST_entry_t。
Page
接着根据
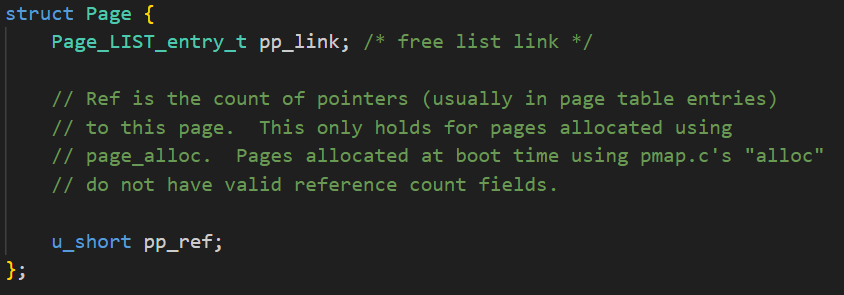
得知
|
|
构成了结构体struct Page。
Page_list
根据
![]()
与

得知
|
|
构成了结构体struct Page_list。
Answer
经过整理总结,也即:
|
|
Thinking 2.4
根据任务指导书:
ASID:Address Space IDentifier
用于区分不同的地址空间。
查找 TLB 表项时,除了需要提供 VPN,还需要提供ASID 同一虚拟地址在不同的地址空间中通常映射到不同的物理地址
在多进程操作系统中,每个进程都有自己独立的虚拟地址空间。ASID 作为唯一的标识符,要用于区分不同进程的地址空间。

ASID通常为8位,即有256种ASID,就可以支持256个不同的地址空间。
Thinking 2.5
调用关系显然:

tlb_invalidate函数通过调用tlb_out函数,把va对应的页表项清空。
其中(va & ~GENMASK(PGSHIFT, 0)) | (asid & (NASID - 1)) 是传入的参数,也就是$a0。
|
|
参考:
Thinking A.1
页面大小4KB,页内偏移为12位。
一级页表指向512个二级页表,每个二级页表指向512个三级页表。
若三级页表的基地址为PTbase,
则三级页表页目录的基地址应当是PTbase + PTbase»9
映射到页目录自身的页目录项地址为PTbase + PTbase»9 + PTbase»18
Thinking 2.6
- 函数调用需要开启进程,env_init就需要pgdir_alloc为其分配页。
- load_icode在加载进程指令代码时,需要page_alloc和page_insert为加载二进制代码到内存而分配物理页并建立映射。
- 当进程结束或内存区域不再使用时使用env_free,需要page_remove从页表移除相关映射,page_decref减少物理页引用计数。
Thinking 2.7
X86 存在逻辑地址、线性地址和物理地址三种地址。
逻辑地址由段基址和偏移量构成,是程序直接使用的地址。
通过分段机制,逻辑地址转换为线性地址;
再利用分页机制,线性地址转换为物理地址用于实际访存。
比较来说,X86有分段和分页两层地址转换,先分段后分页;
MIPS主要是分页机制,内存管理粒度更统一。
难点分析
本次实验整体来说看还是蛮大的,从物理内存到虚拟内存再到TLB,形成了综合的一体化架构。
pmap.c
pmap.c是本次实验最核心的文件之一。主要函数如下:
mips_detect_memory: 得知可用物理页数
alloc:增大freemem,返回申请的物理空间
mips_vm_init:为两级页表alloc物理空间
page_init:把物理空间划分为物理页,根据freemem区分已用页与未用页,并将未用页都放进page_free_list
page_alloc:从page_free_list申请物理页
page_free:将物理页放回page_free_list
pgdir_walk:得到va对应的二级页表中的对应项的索引
page_insert:建立pgdir_walk找到的项与物理页的映射
page_lookup:找到va对应的物理页
page_decref:降低物理页引用次数,降低到0时自动执行page_free
page_remove:降低va对应物理页的引用次数,并清空va对应的TLB表项
其中关于Pde、Pte指针的阅读理解难度比较大,并且涉及到大量的头文件,需要反复阅读pmap.h与queue.h才能解决问题。
TLB
关于TLB表项的清空与重填,我们主要进行阅读与理解的工作。
- 由于TLB miss,do_tlb_refill被触发。
- do_tlb_refill为_do_tlb_refill传参
- _do_tlb_refill调用tlb_invalidate进行TLB清空
- _do_tlb_refill寻找page并进行页表重填
- _do_tlb_refill返回值用于do_tlb_refill重填TLB
实验体会
第一次接触这些内容的时候,会感受到一片茫然。不过实验指导书从内到外的引导还是很到位的,跟着指导书读完源代码后,基本上知道内存管理干了什么事,是如何实现的。
在具体实现代码内容的时候,基本上是被HINT牵着走,没有HINT的话,我也确实不能直接明白该怎么去实现具体的功能。
Lab2只顺着过一遍大抵是会忘光的。如果能够为所有的函数都写上自己的注释,可能理解会更加深入一点。
近期事务很多很乱,如果能像解决Lab2的诸多函数一样,逐个攻克,希望会有好的结果。