
迭代过程综述
请求的迭代
第一次作业:PersonRequest
第二次作业:ScheRequest
第三次作业:UpdateRequest
分配的迭代
第一次作业:指定分配
第二次作业:手动分配、SCHE静默
第三次作业:Update静默、高低楼层分配
运行的迭代
第一次作业:LOOK
第二次作业:专属SCHE运行
第三次作业:专属UPDATE运行、重写MOVE方法
输出的迭代
第一次作业:ARRIVE/OPEN/OUT/IN/CLOSE
第二次作业:SCHE、RECEIVE以及OUT-F/S
第三次作业:UPDATE
迭代分析
作业核心内容
hw5核心实现:
- 生产者消费者模型
- LOOK算法
hw6核心实现:
- 调度器
- SCHE策略
hw7核心实现:
- UPDATE策略
- 强制中转
- 双轿厢的同步与互斥
UML类图
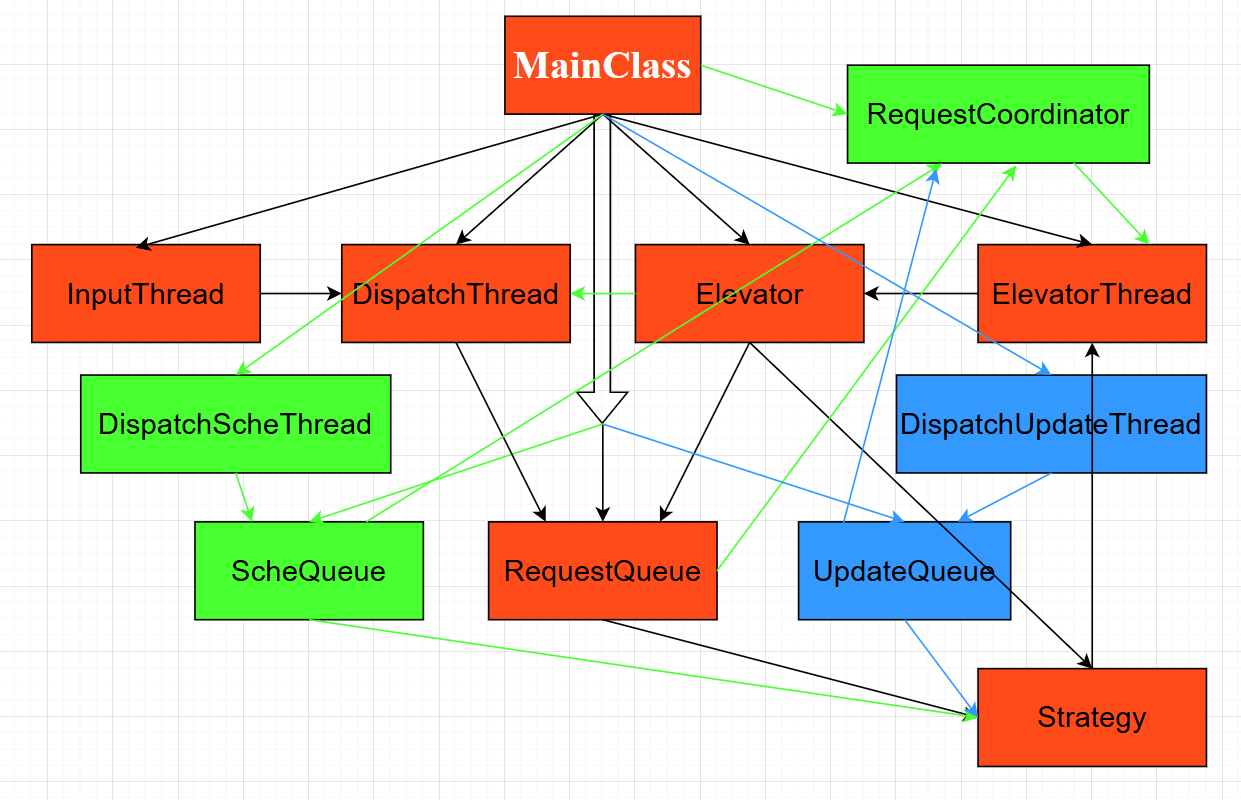
红色为hw5,绿色为hw6,蓝色为hw7
其中对于RequestCoordinator,每个电梯都有一把这样的锁,当电梯没有request时,就会调用这个里的条件变量的wait,也即封装好的waitForRequest()函数。被唤醒则通过分发线程分给各个Queue后触发唤醒。
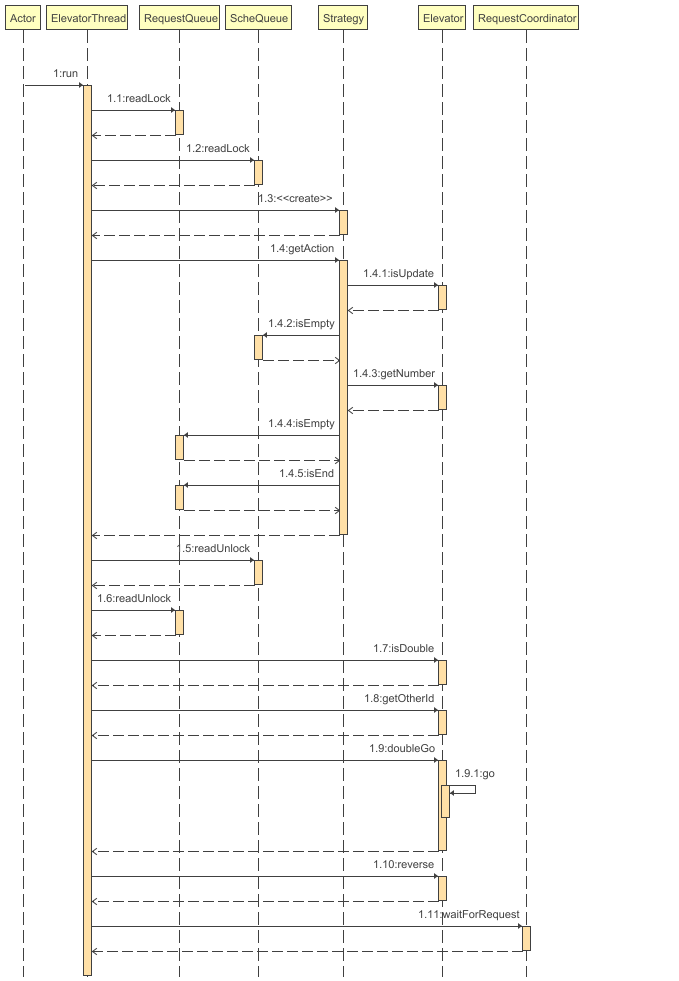
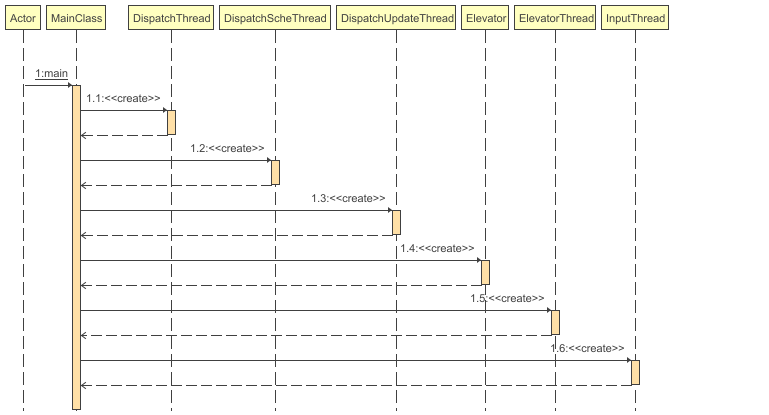
sequence
电梯线程的run方法:
主线程(?)的main方法:
稳定与易变
稳定:
生产者消费者模型的整体框架与类的构建
strategy中的LOOK算法
poll、open、setEnd等基本函数的实现
易变:
具体的运行方法,如doubleGo()、sche()、update()
电梯的属性要不断增添以适应需求
整体感受下来,
hw5是初识多线程、生产者消费者模型与LOOK算法,主要是接受多线程的并发感,掌握一对一的通信方法(End的实现)
hw6开始出现单锁双开:不再是一对一的通信,scheRequest与personRequest都能让正在wait的电梯苏醒。
hw7则出现了更加复杂的线程通信。主要体现在同类对象同一方法过程中的互相通信。如果不做好同步就擅自拿锁,很容易触发死锁。
同步块的设置和锁的选择
在第一次作业中,我基本掌握了synchronize块的用法,配套使用wait与notify。到了第二次作业,我突然决定尝试使用读写锁。在自学了条件变量及其await和signal后,我由于不熟悉、不确定而深受其扰,也常常感到后悔为何要自作主张,但逐渐地,也终于感受到了读写锁的清晰与直白。
在两者的关系上:
同步块其实是隐式使用了对象的内置锁
而显式锁可以跨方法使用,可以设置公平性,还更加清晰易读。
条件变量的引入与传递也极大便利了线程之间的通信。
调度器设计
虽然我采用了随机分配的策略,但是在正确性上要考虑的问题依旧存在。
被SCHE/UPDATE时不能RECEIVE
在调度器中当然需要拿到电梯的相关信息,六部电梯Elevators是调度器的属性之一。
但是在判断到isSche()后,我并不采用重新选电梯的方法,而是用wait方法等待这个电梯SCHE结束,再把那个任务分配给电梯。
这样写自然是有缺陷的,你的调度器线程居然为了一个随机分配的结果而等待?
但是正相对地,他保证了分配结果一定是完全随机的。(hw6 mid5的教训)
此外,随机性也导致等待这一现象的发生也是随机的,并不容易导致调度器被恶意阻塞。
不能RECEIVE我接不到的人
一旦你被升级,且RECEIVE了你接管范围外的人:
在接到这个人之前,你将没有机会把RECEIVE转让。
而你也并不能接到这个人。
在这里,我则强制让它的伙伴来接。
何为范围外:
|
|
同步与防撞设计
在这两处上我都是用了信号+while+sleep的方法。
他看起来很像轮询,但他可慢太多了,循环的次数不会超过15次。
同步启动UPDATE
当电梯满足UPDATE条件时,我会设置该电梯的canUpdate属性为true。
当upper电梯已经setCanUpdate(true),试图发送UPDATE-BEGIN之前,
在大家准备sleep(1000)之前,
便会经历
|
|
电梯防撞
我将transferFloor楼层的运转高度规范化。
对于advice为GO时,会根据当前电梯是否为双轿厢而执行go()或doubleGo()
doubleGo()存在一个判断,就是你是不是正在前往transferFloor。
如果不是就正常go,如果是的话,会触发:
|
|
和一个tryToGo()操作。
tryToGo()会直接先把电梯的楼层设置为transferFloor,避免撞车。接着进行睡200与输出ARRIVE,接着进行开门放人与进人,接着关门和离开这一楼层,最后再更新电梯楼层。
核心目标就是transferFloor的操作要尽可能的规范与固定,这样虽然死板,但是可控性很强。
BUG与DEBUG
不忍提及。本次作业的滑铁卢是我始料未及的,也许从我放弃搭评测机的那一刻就决定了…
没有评测机的话,我只能识别出最基本的RTLE与CTLE。
hw5没有什么好说的。
hw6已经初现端倪:强测1bug,互测1bug
hw7的bug已经数不胜数了。
这其中最最重要的原因,就是DispatchThread的终结控制。
实际上,这可能是我这一整次迭代作业最大的败笔。
一般来说,应当设置一个计数器,记录request的完成情况。没有完成就不要让分发线程终结。对于需要重新分发的请求,只需要扔回分发线程即可。
可我并非如此。
我所有的OUT-F、SCHE、UPDATE导致的无效化,全部都是手动分配电梯,手动输出RECEIVE。
这么做的漏洞: RECEIVE重复!
可能你一个任务被dispatch分发给了电梯A,而电梯A自身的RECEIVE逻辑与dispatch并没有沟通交流,使得电梯A极有可能把dispatch给他的新请求当作无效请求分配出去。除此之外,其他电梯给电梯A分配的新请求在某种时机下也会被重新分配。
但是只要交给dispatch,RECEIVE一定能在这个电梯离开无效状态后才会分配给他。
其实本质上就是,自己由于对死锁的畏惧,并没有增添电梯对分发线程的信息获取。
直到bug修复阶段,经过评测机的重重评测,我在重构了receive和发现隐藏bug后,终于实现了稳定通过bug修复。
评测机是必要的!OOU2不能没有评测机!
心得体会
今天回顾了OOU1的单元总结。哈,还真是高高在上呢。
直到现实重击才清醒过来吗?优美的层次化结构并不是轻易就能实现的。
在bug修复的重重测试之下,终于交出一份满意答卷后,方才意识到自己的问题,竟在于没有做好elevator到requestQueue的回撤,导致自己自行添加了混乱的数据线,毁坏了原有的逻辑链条。在大家都在de撞车、de静默状态RECEIVE的同步问题时,我却在为自己特有的无意义实现而缝缝补补。
层次化结构很重要,也很值得考量。要在局部书写的时候尽力保有全局观。
至于线程安全,我认为线程之间的通信接口主要就是getter与setter,只是取当前时间的情况进行策略决断,可以避免长时间占用锁。
此外避免死锁可以通过规避相互调用。尤其是在两个同类线程在相互上锁的时候,死锁率极高。因此一般考虑用对地位不等、也就是不会相互调用的两个对象上锁,例如在做receive回撤的时候,就直接返回到allrequest中,对它上锁当然是不会死锁的。
在电梯反复运行中感受时间的流逝,从线程的独立与交融中培养多核大脑。