
说在前面
能通过P5实在是很好的一件事。
在我第一道题直接AC确定课下无bug,在我很快做出前两道题确定自己能通过后,我真的如释重负。
题目并不难,在课下提交截止前找出bug并修复真的是我能通过P5的重要原因。
反思前两题,还可以做得更快。思路清晰,才能更精准更利索。
上次也说到了,咱们的P6要实现30条指令了!
具体地说: add, sub, and, or, slt, sltu, lui, addi, andi, ori, lb, lh, lw, sb, sh, sw, mult, multu, div, divu, mfhi, mflo, mthi, mtlo, beq, bne, j, jal, jr, nop
接下来,我们就开始吧!
设计文档
本次P6搭建,我还是选择采用边搭建边写设计文档的方法。
通过记录设计文档来记录我的每一步更改进度,对于P6这种考验严谨性的工程是较有益的。
P6的主要任务,是在一个相对完善的架构上去增添大量的同类型新指令和少量的特殊指令。
add, sub, and, or, slt, sltu, lui,
addi, andi, ori,
lb, lh, lw, sb, sh, sw,
mult, multu, div, divu, mfhi, mflo, mthi, mtlo,
beq, bne, j, jal, jr,
nop
比较新鲜的指令有set型,字节访存,还有最特别的乘除模块指令!
我的搭建逻辑是最后处理乘除模块,先搭简单的,或者说白了,先搭非乘除模块()
顶层模块的改装
由于P6修改了IM和DM模块,在外部接入指令存储器与数据存储器,并在外部实现写入内容的输出
对于这些新的接口,
|
|
为了较少地改动我们的原版CPU,我们采用
assign 顶层输出信号 = 部件输入信号
assign 部件输出信号 = 顶层输入信号
的方式进行书写。
相当于:本来传给IM,DM部件的信号现在要作为顶层输出信号传给外部IM,DM、
而本来从IM和DM部件得到的数据现在要由外部IM,DM通过顶层输入信号进行赋值。
其中只有m_data_byteen这一信号是我们从未出现过的,它涉及到了lh,lb,sh,sb四条新指令。
DM的写
不难设计一个STORE模块:
|
|
在顶层,我们可以直接将m_data_byteen与byteen接口相连
也可以新建信号以提高可扩展性
DM不需要读使能,它始终会读出该地址存储的值,只是后续再通过WdSel来判断你用不用这个信号罢了
而且DM的写使能也很方便实现: |byteen ,将它的各位或起来就可以作为写使能,即存在1就要写。
byteen本身又是控制信号,即哪是1哪被写。
DM的写就基本完成了 (毕竟功能本身已经由testbench全权负责了)
! 这样的执行逻辑与MARS是不同的!经过和学长的交流,m_data_wdata跟MemData显然应当是不同的。
在此加入对MemData做处理的语句,也不难写
|
|
DM的读
前文也说到,DM一直会读,但是lw,lh,lb就需要你来处理了。
根据读出的整个字和控制信号,我们可以实现把MemReadData变成正确的值。
相应地,我们需要通过一个模块将m_data_rdata变为MemRead
再将MemRead赋值给MemReadData(同样是为了可扩展性)
这个模块也很好写:
|
|
IM
这个就不用说了,两句话的事
|
|
sh,sb,lh,lb
做事做到底,就把他们直接都写完吧
书写逻辑:
1.CTRL各项控制信号添加 (和lw,sw完全对应一致)
2.CTRL中Tuse,Tnew (和lw,sw完全对应一致)
3.具体实现(已完成)
简单的E级ALU写数指令
这类指令也很简单,在此也只有两类:
add型: add, sub, and, or
ori型:addi, andi, ori
(在此add型再添加:slt, sltu
原因在下一小节
读两个数 算一个数
也就是add型指令
把它归为同一类的原因,主要是控制信号过于相似:
相同调控(置相同的数)的信号有:WrSel, RFWr, Tuse_rs, Tuse_rt, Tnew_D
特异性的信号是ALUOp,用宏定义增强可读性
书写时要额外注意slt和sltu
|
|
读一个数 拿一个立即数 算一个数
也就是ori型指令
其实和上一类很像,不过区别在于:
num_2是IMM_32而非V2 写的寄存器是rt而非rd
相同调控(置相同的数)的信号有:RFWr, ImmSel, Tuse_rs, Tuse_rt, Tnew_D
!特异性: ADDI是符号扩展 ,ORI,ANDI是零扩展
D级算数指令
真的要在D级算数?
这是我之前从未触及的一个点。在此,为提高效率,我将冒险进行优化:
这类指令有slt, sltu, lui, jal
把它们前移至D级改变了两件事:Tnew降低、Tuse降低
我之前并没有写过E-D转发,使得lui和jal的Tnew均为1
经过优化,他们的Tnew可以变成0,从而避免后续指令被阻塞
但他们也有风险:风险就是Tuse降低使得他们本身的操之过急可能会使自己被阻塞
事实上,lui和jal是直接对立即数操作,因此并没有Tuse的风险问题。
而slt和sltu则有风险。
因此我将slt和sltu放回了简单的E级ALU写数指令。
lui 和 jal 的 E->D转发
接下来先说说我对lui和jal的改进吧。
首先,jal的转发十分简单,只要当A1(A2)等于31且Link_E时把pc+8传过去而已。
jal在后面把这个值选择赋给了ALUData_E_True,即
|
|
那么相应地,lui的转发也可以很简单。
真正要写入寄存器的lui的值当然还是ALU算出来的,相当于节省了把这个值选择赋给ALUData_E_True的过程。
lui未曾有的,是他的独特信号,即Lui
lui要转发的值,就是{IMM32_E[15:0], 16’b0}
由于后续由ALU承包,Lui信号只需要坚持到E->D转发就够了
可知我们需要改动CTRL,D_E这两个子模块。
那么咱们的成效就要显露出来了:
那就是减少阻塞!Tnew降为0!
在CTRL中更改Tnew信号后,这一段路,也算是走完了。
跳转指令
增添的新指令是bne
已经可以称得上和beq完全一致了吧…
主要差别只在于zero和!zero
相同调控(置相同的数)的信号有:PCSel, Tuse_rs, Tuse_rt, (Tnew都不存在)
不过bne和beq要区分,所以还是需要有控制信号传出来。
主要就是NPC引入新接口bne,参与了npc的计算罢了
|
|
接下来,剩下的8个乘除模块指令,就要从零建起了。
乘除模块
乘除模块共8条指令
mult, multu, div, divu, mfhi, mflo, mthi, mtlo
MDALU模块
我们可以构建模块MDALU
接口如下所示:
| 名称 | 位宽 | 方向 |
|---|---|---|
| clk | 1 | I |
| reset | 1 | I |
| MDALUOp | 4 | I |
| num_1 | 32 | I |
| num_2 | 32 | I |
| start_busy | 1 | O |
| busy | 1 | O |
| HI | 32 | O |
| LO | 32 | O |
clk和reset的功能就不多说了,要清空所有寄存器
start_busy:得知指令为 mult,multu,div,divu,引发运算,阻塞与busy
(在start_busy的时候就要为下一周期阻塞了,再不阻塞E级就要进来新指令了)
MDALUOp:控制信号
|
|
busy:这个可以说是最重要的一个点。
在busy状态下,我们要进行阻塞,Pc、F_D级不动,D_E级清空,E级及以后顺延运算。
问题的关键在于:
如何控制busy时间?
以乘法为例:
每个时钟上升沿,start_busy信号为1时,给cnt归0,给busy赋1,算出LO,HI要被赋的值(现在再不算,等会阻塞的时候E级都清空了)
(由于非阻塞赋值,在下一时钟上升沿cnt = 0, busy = 1)
busy为1时,
- 若
cnt == 4,busy和cnt清零,并对regHI,regLO赋值
(由于非阻塞赋值,第五个时钟周期开始时cnt刚被赋值为4,
那么下一个时钟上升沿是busy和cnt都清零,regHI和regLO被赋值,
assign语句的即时性使得HI与LO直接出值) - 否则cnt++
指令的控制信号
这八条指令除了MDALUOp以外,也有其对应的控制信号要处理。
mult,multu,div,divu是完全同质的指令。
特点是读GRF,直接写HI,LO,不写GRF和DM
可以归纳其控制信号RFWr = DMWr = DMRd = 0;
ImmSel = 0;运算数都是寄存器
Tuse_rs = Tuse_rt = 3’b1;
乘除法的Tnew不必担心:
得出结果就直接塞到寄存器里了
新指令一旦进来,就说明我的regHI和regLO已经写好了
转发都不用,更别说阻塞了
再说了,乘除法不差你这一点阻塞,本身阻塞的也够多了()
mfhi,mflo是一个访存指令。
要读HI,LO,写GRF
这考虑的就要多了。
首先,它写GRF,就决定了它需要去转发:
指令的Tnew = 1,可进行M->D,M->E的转发。
我们当然可以直接把它加入ALUData_E_true(像当初pc+8那样)
其次,写要写到哪:rd
那么WrSel要置1
另外,写当然需要写使能:RFWr = 1
mthi,mtlo要对HI和LO进行写
要读GRF 写HI,LO
那么其实这和第一类指令很相似
不写GRF和DM,控制信号RFWr = DMWr = DMRd = 0;
ImmSel = 0;运算数都是寄存器
特点是Tuse_rs = 3’b1;
但是不需要读GRF[rt]
同样类似地,它的值也是即拿即写
不需要转发与阻塞
指令在模块内的书写
前四条已经较详细地描述过了
但在实际书写上,还是存在一定问题:
1.
在阻塞之后,什么值都丢了,那么你就必须有自己预先存好的Op,预先存好的计算结果,才能使得你这个周期还能按着原来的指令的轨迹去走。
但是,op你应该怎么存?
这至少需要一个时钟周期去存它,那么如果你只根据Op判断,你就已经丢失了一个时钟周期。不仅如此,对于一个周期就能完成的mf,ml指令而言,这更是荒唐。
因此,我目前的写法是不仅对Op写case语句,还对MDALUOp写case语句。
那么,Op的控制也应更加严格,即执行完语句后,应把Op置为`NONE。
(注意:default的情况不要对Op处理!因为default可能是还没来得及赋值的Op,这下好了,同一上升沿两次赋值)
符号乘法要怎么写?
鉴于曾经在这里WA过一发,我在此直接给出写法:
|
|
就这么简单。不要担心位宽不一致。它会自动扩展。
mf指令是一个读HI,LO指令,而我们的HI与LO本就一直在输出。
只需要MDALUOp的控制信号管理一下ALUData_E_true的选择即可。
mt指令为写HI,LO指令,直接在case语句里面写寄存器就行。
!!这里要注意,我们写HI,LO寄存器其实是在下一时钟周期才完成的
因此有人会担心,如果下一条指令就要读HI,LO会不会出错误?
答案是不会。因为我们的assign一直在输出,HI,LO被写之后拿出来的数肯定是对的。
曾经又在这里WA过一发:mt指令读的都是rs!!!
模块在顶层的书写
作为少有的要改动顶层模块的设计
首先要注意先前所提到的
mf指令涉及到的写寄存器与转发的问题,都需要靠ALUData_E_true来解决
|
|
当然还有模块本身的接口及其信息传递
另外要注意的就是阻塞:
阻塞实际上也就是多 或上了两个信号start_busy和busy信号
并非如此!
阻塞应该或上start_busy信号清空E级倒没错(防止ALUOp不变回0引发两个case语句都被执行)
但是busy信号应当与MDALUOp_E与起来再或
因为乘除的结果放进HI,LO里是不影响其他指令的进行的,只有遇到与HI,LO相关的语句,我们才有阻塞的必要。
通过这样优化,大大降低了阻塞率。
那么接下来的,就是大量指令引发的巨量测试。
测试文档
单个指令的测试
对于新加入的指令本身,我们需要进行一次较为彻底的测试。
一是功能本身的基础是否实现,二是一些特殊情况需要验证。
首先是lh,lb,sh,sb指令:
侧重对符号扩展的测试
对于add, sub, and, or, slt, sltu, lui, addi, andi, ori
要注意addi的符号扩展是否做到
对于bne就正常测试成功or失败跳转即可
对于乘除法模块则也要注意符号问题
这一层次的测试基本上是用于debug的,因为只涉及自身功能,不涉及冒险,课下的弱测强度基本足够了。
当然还是建议自行做足测试的。
指令之间的冲突处理
利用思考题处的表格自行构造样例,再结合评测机进行测试。
我决定写多个小型测试,对各种转发与阻塞的情况编写特别代码来检测结果。在此不便展示。
思考题
为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
因为乘除法部件的运算逻辑与读写数据都与ALU截然不同。
首先,乘除法的高强度阻塞与特别的时序逻辑决定了他不能和组合逻辑直接混用。
乘除法模块中计算指令就不说了,mf指令是组合逻辑assign,mt指令是写寄存器的时序逻辑。这和原ALU是不太兼容的。
其次,HI,LO寄存器也只有MDALU能用到,和ALU混用,就提高了内部耦合度,显得混乱。
这么做,把计算分为ALU和MDALU,最后再进行选择,其实相当于是形成了一个更大的ALU,含有原ALU和MDALU。因此,单独的乘除法部件更好地做到了“高内聚,低耦合”。
最大的好处:先前没有理解好乘除法的阻塞,事实上,只要乘除法运算过程中没有与乘除类有关的指令,就不需要阻塞。那咱们的效率可谓是大大提升了。
独立的HI,LO:
首先,HI,LO有其自身特殊性,不能被直接读,只能靠mf指令读。
其次,把HI,LO放在E区,与其他寄存器分离开来,能够实现即出即写,避免了读写冲突。
真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
经过资料查阅,在真实的流水线CPU中,32位乘法是分部分计算的,一个周期可以32位对8位数的乘法(?),然后4个周期能算完。
除法据说是用试商法,一次试4位,8个周期做完除法。
请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
start可以引发busy,而start和busy都能导致阻塞。
通过计数器控制阻塞周期数,在最后一周期,清空busy,cnt,并完成寄存器赋值。
由于阻塞清空了E寄存器,我将MDALUOp和运算结果进行了及时存储。当然,在最后一周期,这些存储的信号也要清空。
请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
清晰性:
提前将DMWr和addr共同作用的结果算出来,清晰明了地表达了究竟要写哪些字节,对每个字节执行独立的赋值。
统一性:
sw,sh,sb都能用同样的按字节赋值的逻辑来执行。
不过需要被写数据要进行一些预处理:
|
|
请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
写入DM的确实只写了一个字节
但从DM获取的是一整个字,要经过后续处理
执行lw和sw时当然还是按字读写更快
但是执行对半字与字节的操作时,按字节读写效率更高
为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
抽象:
我对指令进行了归类,如设计文档所示。并按类地添加和处理指令
最显著的作用如DMRd,DMWr,ALUOp,MDALUOp等等,单个多位信号传入流水线寄存器,相较于多个单位信号是更方便的。
规范:
对于同一类指令,可以对其先归为一类,再统一为控制信号赋值
(其实也没简单太多,比如addi这种符号扩展,还要单独写)
帮助:
在译码和处理数据冲突的时候也就是在CTRL内,按类调整控制信号与T信号,省时省力
在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
新的冲突只有数据冒险。处理方法也别无二致。
阻塞:
我在修改CTRL的时候,已经为各个指令赋好了Tuse_rs,Tuse_rt,Tnew,阻塞正常进行
转发:
新添的所有指令中,需要的位点没有改变:V1_D,V2_D,num_1,num_2(此处忽略lh,lb.sh,sb)
新添的所有指令中,写寄存器的内容:大多都还是原来的路径,除了M级有新数据:即来自LO,HI的新数据。(要知道乘除运算指令本身是不写GRF的)
对于这个的处理前文也有提及:
|
|
对于这个改动的测试样例:
|
|
这个样例过多测试了M->E转发,下面补充一个M->D转发
|
|
如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
我采用了手动构造法。
通过建立策略矩阵,按照T的关系来进行构造
具体分类方式如下图所示:
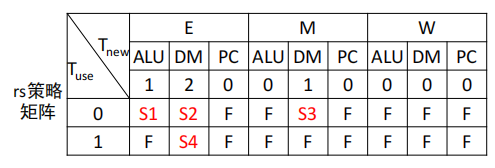
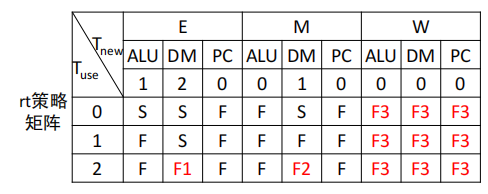
这两张图还需添加关于lui和mf指令的测试,单独对这两个指令构造测试也是可行的。